
Una interrupción generalizada del servicio el 20 de octubre dejó temporalmente fuera de servicio a varias plataformas importantes después de una falla importante en la infraestructura de Amazon Web Services (AWS).
Aplicaciones populares como Snapchat, Fortnite y Alexa se volvieron inaccesibles durante horas, exponiendo hasta qué punto gran parte de Internet depende de unos pocos grandes proveedores de nube.
La interrupción de AWS expuso los puntos débiles de Web2 y cómo los diseños de Web3 agregan resiliencia
El evento destacó hasta qué punto Internet global depende de un pequeño número de proveedores de nube centralizados. También renovó las discusiones sobre modelos alternativos, en particular los sistemas descentralizados promovidos bajo Web3, que tienen como objetivo reducir la dependencia de puntos únicos de falla.
Los informes de problemas de conectividad comenzaron alrededor de las 3:11 a.m. ET, cuando los usuarios de los Estados Unidos y partes de Europa notaron que varias aplicaciones y sitios web habían dejado de funcionar.
Amazon pronto confirmó que su región US-East-1, uno de sus centros de nube más críticos, estaba experimentando «tasas de error elevadas» que afectaban a servicios como API Gateway, Lambda y CloudFront.
En una hora, las plataformas que dependen del alojamiento de AWS, desde el entretenimiento hasta los servicios comerciales, comenzaron a apagarse. La interrupción de AWS interrumpió las operaciones principales en múltiples industrias, incluidos el comercio electrónico, los juegos, las comunicaciones y los servicios financieros.
Durante varias horas, los usuarios no pudieron acceder a las funciones del hogar inteligente, iniciar sesión en plataformas sociales o completar transacciones en línea. Las empresas que operan en entornos basados en AWS también enfrentaron tiempo de inactividad en sus sistemas internos, lo que interrumpió las operaciones diarias y los servicios al cliente.
Causa raíz de la interrupción de AWS: lo que Amazon confirmó
Al mediodía, los ingenieros de Amazon identificaron una configuración incorrecta en una actualización de red como la causa principal. El problema interrumpió la forma en que los sistemas internos administraban las operaciones de enrutamiento y DNS, lo que impedía que las solicitudes llegaran a sus destinos. Los equipos de AWS revirtieron la actualización defectuosa, restaurando gradualmente el servicio completo a última hora de la tarde.
Amazon enfatizó que no se perdieron ni comprometieron datos de los clientes, y que el problema se limitó a una sola región. Aún así, el tiempo de inactividad destacó cómo incluso un problema localizado puede extenderse a través del ecosistema web global cuando tantos servicios digitales dependen de una sola capa de infraestructura.
Qué sitios web y aplicaciones se cayeron y por qué se extendió el impacto
Entre las interrupciones más visibles se encuentran los propios productos de consumo de Amazon, incluidos Alexa y Ring. Los usuarios informaron que los altavoces inteligentes no procesaron los comandos de voz, mientras que las cámaras y los timbres conectados dejaron de responder a los controles de las aplicaciones móviles.
En el sector del entretenimiento y los juegos, títulos como Fortnite, Roblox y PUBG experimentaron errores de inicio de sesión y fallas en el emparejamiento. Muchos de estos juegos dependen de AWS para la sincronización multijugador en tiempo real y la entrega de contenido basado en la nube.
Las plataformas sociales y de comunicación también se vieron afectadas. Los usuarios de Snapchat tuvieron dificultades para enviar mensajes y cargar feeds durante el pico de la interrupción. Además, Slack, Zoom y varias herramientas empresariales basadas en la infraestructura de AWS informaron problemas de conectividad intermitentes que afectan las operaciones de trabajo remoto.
Algunas aplicaciones financieras y procesadores de pagos que utilizan los servicios de computación y almacenamiento de AWS se desconectaron brevemente, lo que provocó transacciones fallidas y retrasos en los pagos digitales. Los sitios web minoristas y de comercio electrónico creados en AWS también experimentaron tiempo de inactividad temporal o tiempos de respuesta más lentos.
Por qué la centralización amplió el radio de explosión en la web
El alcance del incidente mostró cuán profundamente AWS está integrado en las funciones diarias de Internet. Una sola interrupción regional se extendió más allá de su geografía inmediata, interrumpiendo los sistemas de consumo, entretenimiento y empresas en múltiples zonas horarias.
Esta falla también destacó cómo las dependencias del servicio, como las API y las integraciones de terceros, pueden propagar los efectos de una interrupción mucho más allá de su origen técnico.
Según el informe posterior al incidente de Amazon, la interrupción se debió a un cambio de configuración defectuoso implementado durante una actualización de mantenimiento de rutina. El cambio alteró involuntariamente la forma en que los solucionadores de DNS internos dirigían el tráfico, lo que provocó que los sistemas dejaran de procesar solicitudes.
Una vez detectada, los ingenieros de Amazon iniciaron una reversión de la actualización y redirigieron el tráfico a través de rutas de respaldo. La restauración comenzó región por región, y el estado de interrupción de AWS mostró una recuperación gradual al final de la tarde.
Desde entonces, la compañía ha introducido salvaguardas adicionales para evitar problemas similares, incluidos controles de gestión de cambios más estrictos y nuevos procedimientos automatizados de reversión para actualizaciones de red.
Centralización vs. descentralización: una lección más amplia
Este incidente reabrió el debate de larga data entre los modelos Web2 y Web3 . En el marco actual de Web2, un puñado de corporaciones, incluidas Amazon, Google y Microsoft, impulsan la mayor parte del tráfico web global a través de servidores centralizados.
Esta estructura ofrece comodidad, rentabilidad y escalabilidad, pero también concentra el control y la vulnerabilidad. Cuando uno de estos proveedores experimenta una interrupción, los efectos son inmediatos y generalizados.
Los analistas de la industria han advertido durante mucho tiempo que esta concentración de poder de alojamiento y gestión de datos crea un único punto de falla para Internet. Si bien la computación en la nube ofrece escalabilidad y rentabilidad, también centraliza el riesgo. Cuando los sistemas de un proveedor clave se caen, los servicios dependientes tienen poco espacio para recuperarse de forma independiente.
La interrupción de AWS también expuso otro desafío, que son las dependencias interconectadas. Muchos servicios operan en arquitecturas en capas donde la API o la base de datos de un proveedor admite múltiples plataformas posteriores. Esta estructura magnifica el impacto de cualquier interrupción técnica.
Los expertos sugieren que, si bien la redundancia y la implementación en varias regiones pueden reducir el riesgo, el problema fundamental radica en cómo está estructurada la web. Los modelos de nube centralizados consolidan el control y la capacidad en unas pocas redes, lo que hace que las fallas sean más impactantes y más difíciles de aislar.
Por qué los expertos ven la Web3 como una alternativa viable
Web3 tiene como objetivo cambiar eso distribuyendo la potencia informática y el almacenamiento de datos a través de redes descentralizadas de nodos independientes. A diferencia de los sistemas centralizados en la nube, las arquitecturas descentralizadas no dependen del tiempo de actividad de un proveedor. Si se produce un error en un nodo o clúster, otros pueden seguir funcionando sin interrupción.
Para los desarrolladores y las empresas, este enfoque podría significar una mayor resiliencia, transparencia y seguridad, aunque escalar la infraestructura descentralizada para que coincida con la velocidad y la capacidad de Web2 sigue siendo un desafío.
Proyectos como Filecoin, Arweave y Akash Network son ejemplos de soluciones de infraestructura descentralizadas que tienen como objetivo proporcionar almacenamiento y potencia informática a través de redes abiertas. Estos sistemas utilizan mecanismos de incentivos para mantener el tiempo de actividad y la disponibilidad de datos sin supervisión centralizada.
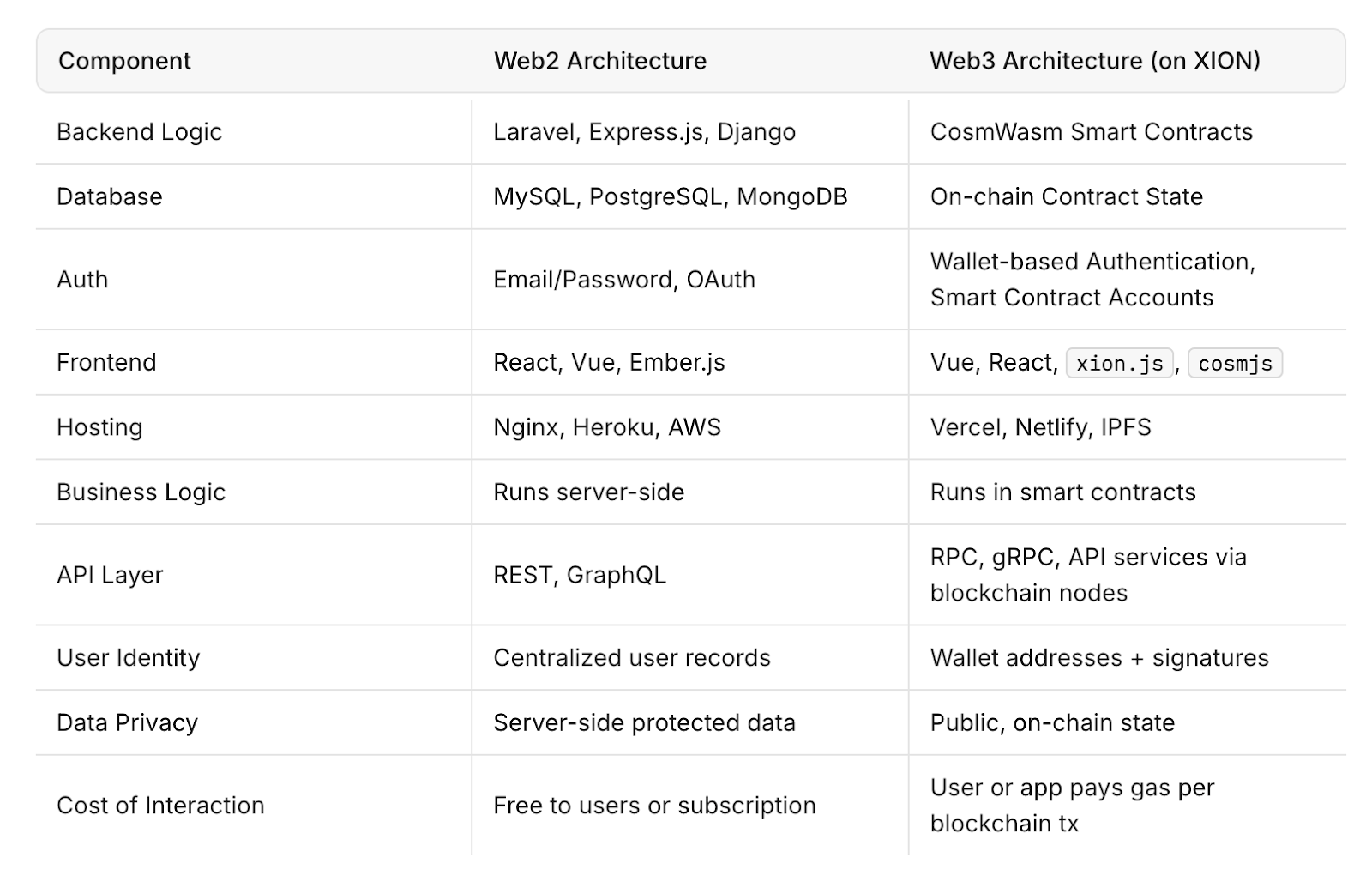
Sin embargo, la infraestructura Web3 aún se encuentra en las primeras etapas de adopción. Se enfrenta a desafíos relacionados con la escalabilidad, la velocidad y la experiencia del usuario en comparación con los sistemas Web2 establecidos. Aun así, el incidente de AWS demostró el valor de tener modelos alternativos que puedan mejorar la resiliencia de Internet.
Lecciones aprendidas y el camino a seguir
La interrupción apuntó al hecho de que la resiliencia en la economía digital requiere redundancia y diversificación. Las empresas que distribuyeron sus cargas de trabajo en varias regiones o proveedores de la nube experimentaron menos tiempo de inactividad y tiempos de recuperación más rápidos. Otros, totalmente dependientes de AWS, se quedaron esperando hasta que Amazon restauró sus sistemas.
También reveló cómo las cadenas de dependencia amplifican las interrupciones. Muchas aplicaciones no alojaban sus servicios principales en AWS, pero aún así se desconectaron porque usaban API, análisis o herramientas de autenticación alojadas en AWS. Un único punto de falla en la cadena desencadenó interrupciones en plataformas no relacionadas.
El evento puede llevar a varias organizaciones a repensar sus estrategias de infraestructura, explorando modelos híbridos que combinan sistemas tradicionales en la nube con almacenamiento y computación descentralizados.
Tanto los desarrolladores como las empresas también pueden ver la descentralización no solo como una tendencia, sino como una salvaguarda práctica contra el tiempo de inactividad a gran escala.
Amazon ha declarado que los nuevos mecanismos de monitoreo y los controles internos de reversión ahora están activos en todas las regiones. Sin embargo, los expertos señalan que las soluciones técnicas por sí solas no pueden abordar completamente los riesgos inherentes a la centralización.
A medida que se profundiza la dependencia digital global, la resiliencia puede depender de la eficacia con la que la computación en la nube y las tecnologías descentralizadas puedan coexistir.
Preguntas frecuentes
¿Qué causó la interrupción de AWS?
Amazon dijo que un error de configuración durante una actualización de rutina en su región US-East-1 interrumpió el enrutamiento de la red y las funciones de DNS. El problema se contuvo en cuestión de horas y no se informaron violaciones de datos o seguridad.
¿Qué sitios web y aplicaciones se vieron afectados?
Plataformas como Alexa, Ring, Snapchat, Fortnite y Roblox se desconectaron. Las herramientas comerciales y de pago que utilizan la infraestructura de AWS también enfrentaron interrupciones temporales.
¿Por qué la centralización hace que Internet sea vulnerable?
Los sistemas centralizados dependen de unos pocos proveedores importantes, por lo que una falla puede afectar a millones de usuarios. Las redes descentralizadas reducen este riesgo al distribuir las operaciones entre nodos independientes.
Conclusión
El incidente de octubre de 2025 reveló las fortalezas y debilidades de la infraestructura moderna en la nube. AWS logró restaurar las operaciones rápidamente, pero los efectos dominó globales demostraron que la confiabilidad tiene límites cuando el control recae en unos pocos proveedores.
Para las empresas y los desarrolladores, la lección aquí es que la diversificación y la descentralización ya no son opcionales. Las infraestructuras híbridas que combinan la eficiencia centralizada con la resiliencia descentralizada podrían definir la próxima era de confiabilidad de Internet.
Disclaimer: The information presented in this article is for informational and educational purposes only. The article does not constitute financial advice or advice of any kind. Coin Edition is not responsible for any losses incurred as a result of the utilization of content, products, or services mentioned. Readers are advised to exercise caution before taking any action related to the company.




