
Uma interrupção generalizada do serviço em 20 de outubro derrubou temporariamente várias plataformas importantes após uma grande falha na infraestrutura da Amazon Web Services (AWS).
Aplicativos populares como Snapchat, Fortnite e Alexa ficaram inacessíveis por horas, expondo até que ponto grande parte da Internet depende de alguns grandes provedores de nuvem.
A interrupção da AWS expôs os pontos fracos da Web2 e como os designs da Web3 adicionam resiliência
O evento destacou até que ponto a internet global depende de um pequeno número de provedores de nuvem centralizados. Também renovou as discussões sobre modelos alternativos, particularmente sistemas descentralizados promovidos na Web3, que visam reduzir a dependência de pontos únicos de falha.
Os relatos de problemas de conectividade começaram por volta das 3h11 ET, quando usuários nos Estados Unidos e em partes da Europa notaram que vários aplicativos e sites haviam parado de funcionar.
A Amazon logo confirmou que sua região US-East-1, um de seus hubs de nuvem mais críticos, estava enfrentando “taxas de erro elevadas” afetando serviços como API Gateway, Lambda e CloudFront.
Em uma hora, as plataformas dependentes da hospedagem da AWS, de entretenimento a serviços comerciais, começaram a ficar escuras. A interrupção da AWS interrompeu as principais operações em vários setores, incluindo comércio eletrônico, jogos, comunicações e serviços financeiros.
Por várias horas, os usuários não conseguiram acessar as funções da casa inteligente, fazer login em plataformas sociais ou concluir transações online. As empresas que operam em ambientes baseados na AWS também enfrentaram tempo de inatividade em seus sistemas internos, interrompendo as operações diárias e os serviços ao cliente.
Causa raiz da interrupção da AWS: o que a Amazon confirmou
Ao meio-dia, os engenheiros da Amazon identificaram uma configuração incorreta em uma atualização de rede como a causa raiz. O problema interrompeu a forma como os sistemas internos gerenciavam o roteamento e as operações de DNS, impedindo que as solicitações chegassem aos seus destinos. As equipes da AWS reverteram a atualização defeituosa, restaurando gradualmente o serviço completo no final da tarde.
A Amazon enfatizou que nenhum dado do cliente foi perdido ou comprometido e que o problema estava contido em uma única região. Ainda assim, o tempo de inatividade destacou como até mesmo um problema localizado pode se espalhar pelo ecossistema global da web quando tantos serviços digitais dependem de uma única camada de infraestrutura.
Quais sites e aplicativos caíram e por que o impacto se espalhou
Entre as interrupções mais visíveis estavam os próprios produtos de consumo da Amazon, incluindo Alexa e Ring. Os usuários relataram que os alto-falantes inteligentes não processaram os comandos de voz, enquanto as câmeras e campainhas conectadas pararam de responder aos controles do aplicativo móvel.
No setor de entretenimento e jogos, títulos como Fortnite, Roblox e PUBG apresentaram erros de login e falhas de matchmaking. Muitos desses jogos dependem da AWS para sincronização multijogador em tempo real e entrega de conteúdo baseado na nuvem.
As plataformas sociais e de comunicação também foram atingidas. Os usuários do Snapchat encontraram dificuldades para enviar mensagens e carregar feeds durante o pico da interrupção. Além disso, Slack, Zoom e várias ferramentas de negócios criadas na infraestrutura da AWS relataram problemas de conectividade intermitentes que afetam as operações de trabalho remoto.
Alguns aplicativos financeiros e processadores de pagamento que utilizam os serviços de computação e armazenamento da AWS ficaram offline brevemente, causando falhas nas transações e atrasos nos pagamentos digitais. Sites de varejo e comércio eletrônico criados na AWS também tiveram tempo de inatividade temporário ou tempos de resposta mais lentos.
Por que a centralização ampliou o raio de explosão em toda a web
O alcance do incidente mostrou o quão profundamente a AWS está incorporada nas funções diárias da Internet. Uma única interrupção regional se estendeu além de sua geografia imediata, interrompendo os sistemas de consumo, entretenimento e corporativos em vários fusos horários.
Essa falha também destacou como as dependências de serviço, como APIs e integrações de terceiros, podem espalhar os efeitos de uma interrupção muito além de sua origem técnica.
De acordo com o relatório pós-incidente da Amazon, a interrupção resultou de uma alteração de configuração defeituosa implementada durante uma atualização de manutenção de rotina. A mudança alterou involuntariamente a forma como os resolvedores internos de DNS direcionavam o tráfego, fazendo com que os sistemas parassem de processar solicitações.
Depois de detectados, os engenheiros da Amazon iniciaram uma reversão da atualização e redirecionaram o tráfego por meio de rotas de backup. A restauração começou região por região, com o status de interrupção da AWS mostrando uma recuperação gradual no final da tarde.
Desde então, a empresa introduziu salvaguardas adicionais para evitar problemas semelhantes, incluindo controles de gerenciamento de mudanças mais rígidos e novos procedimentos automatizados de reversão para atualizações de rede.
Centralização vs. Descentralização: Uma Lição Mais Ampla
Este incidente reabriu o debate de longa data dos modelos Web2 vs Web3 . Na atual estrutura da Web2, um punhado de corporações, incluindo Amazon, Google e Microsoft, alimenta a maior parte do tráfego global da web por meio de servidores centralizados.
Essa estrutura oferece conveniência, economia e escalabilidade, mas também concentra controle e vulnerabilidade. Quando um desses provedores sofre uma interrupção, os efeitos são imediatos e generalizados.
Analistas do setor há muito alertam que essa concentração de poder de hospedagem e gerenciamento de dados cria um único ponto de falha para a Internet. Embora a computação em nuvem ofereça escalabilidade e eficiência de custos, ela também centraliza o risco. Quando os sistemas de um provedor de chaves ficam inativos, os serviços dependentes têm pouco espaço para se recuperar de forma independente.
A interrupção da AWS também expôs outro desafio, que são as dependências interconectadas. Muitos serviços operam em arquiteturas em camadas em que a API ou o banco de dados de um provedor oferece suporte a várias plataformas downstream. Essa estrutura amplia o impacto de qualquer interrupção técnica.
Especialistas sugerem que, embora a redundância e a implantação em várias regiões possam reduzir o risco, o problema fundamental está em como a web é estruturada. Os modelos de nuvem centralizados consolidam o controle e a capacidade em algumas redes, tornando as falhas mais impactantes e mais difíceis de isolar.
Por que os especialistas veem a Web3 como uma alternativa viável
A Web3 visa mudar isso distribuindo poder de computação e armazenamento de dados em redes descentralizadas de nós independentes. Ao contrário dos sistemas de nuvem centralizados, as arquiteturas descentralizadas não dependem do tempo de atividade de um provedor. Se um nó ou cluster falhar, outros poderão continuar operando sem interrupção.
Para desenvolvedores e empresas, essa abordagem pode significar maior resiliência, transparência e segurança, embora dimensionar a infraestrutura descentralizada para corresponder à velocidade e capacidade da Web2 continue sendo um desafio.
Projetos como Filecoin, Arweave e Akash Network são exemplos de soluções de infraestrutura descentralizada que visam fornecer armazenamento e poder de computação por meio de redes abertas. Esses sistemas usam mecanismos de incentivo para manter o tempo de atividade e a disponibilidade de dados sem supervisão centralizada.
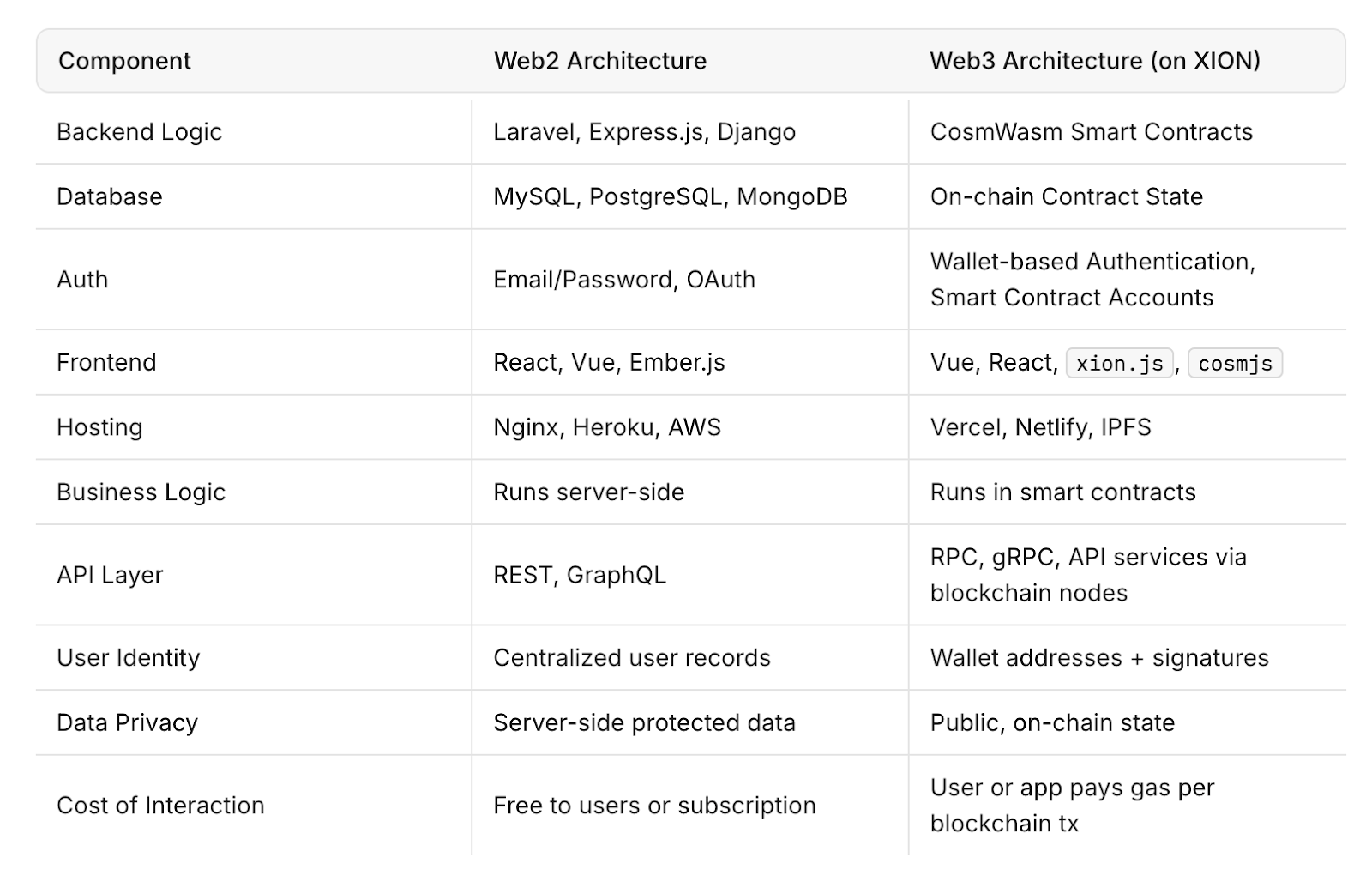
No entanto, a infraestrutura Web3 ainda está nos estágios iniciais de adoção. Ele enfrenta desafios relacionados à escalabilidade, velocidade e experiência do usuário em comparação com sistemas Web2 estabelecidos. Mesmo assim, o incidente da AWS demonstrou o valor de ter modelos alternativos que podem aumentar a resiliência da Internet.
Lições aprendidas e o caminho a seguir
A interrupção apontou para o fato de que a resiliência na economia digital requer redundância e diversificação. As empresas que distribuíram suas cargas de trabalho em várias regiões ou provedores de nuvem tiveram menos tempo de inatividade e tempos de recuperação mais rápidos. Outros, totalmente dependentes da AWS, ficaram esperando até que a Amazon restaurasse seus sistemas.
Também revelou como as cadeias de dependência amplificam as interrupções. Muitos aplicativos não hospedavam seus serviços principais na AWS, mas ainda ficavam offline porque usavam APIs, análises ou ferramentas de autenticação hospedadas pela AWS. Um único ponto de falha na cadeia desencadeou interrupções em plataformas não relacionadas.
O evento pode levar várias organizações a repensar suas estratégias de infraestrutura, explorando modelos híbridos que combinam sistemas tradicionais em nuvem com armazenamento e computação descentralizados.
Desenvolvedores e empresas também podem ver a descentralização não apenas como uma tendência, mas como uma proteção prática contra o tempo de inatividade em grande escala.
A Amazon afirmou que novos mecanismos de monitoramento e controles internos de reversão estão agora ativos em todas as regiões. No entanto, os especialistas observam que as correções técnicas por si só não podem resolver totalmente os riscos inerentes à centralização.
À medida que a dependência digital global se aprofunda, a resiliência pode depender da eficácia com que a computação em nuvem e as tecnologias descentralizadas podem coexistir.
Perguntas frequentes
O que causou a interrupção da AWS?
A Amazon disse que um erro de configuração durante uma atualização de rotina em sua região US-East-1 interrompeu o roteamento de rede e as funções de DNS. O problema foi contido em poucas horas e nenhuma violação de dados ou segurança foi relatada.
Quais sites e aplicativos foram afetados?
Plataformas como Alexa, Ring, Snapchat, Fortnite e Roblox ficaram offline. As ferramentas de negócios e pagamento que usam a infraestrutura da AWS também enfrentaram interrupções temporárias.
Por que a centralização torna a internet vulnerável?
Os sistemas centralizados dependem de alguns provedores importantes, portanto, uma falha pode afetar milhões de usuários. As redes descentralizadas reduzem esse risco espalhando as operações por nós independentes.
Conclusion
O incidente de outubro de 2025 revelou os pontos fortes e fracos da infraestrutura de nuvem moderna. A AWS conseguiu restaurar as operações rapidamente, mas os efeitos globais mostraram que a confiabilidade tem limites quando o controle está com alguns provedores.
Para empresas e desenvolvedores, a lição aqui é que a diversificação e a descentralização não são mais opcionais. Infraestruturas híbridas que combinam eficiência centralizada com resiliência descentralizada podem definir a próxima era de confiabilidade da Internet.
Disclaimer: The information presented in this article is for informational and educational purposes only. The article does not constitute financial advice or advice of any kind. Coin Edition is not responsible for any losses incurred as a result of the utilization of content, products, or services mentioned. Readers are advised to exercise caution before taking any action related to the company.




