
Le 20 octobre, une interruption de service généralisée a temporairement mis hors ligne plusieurs plates-formes majeures après une défaillance majeure de l’infrastructure d’Amazon Web Services (AWS).
Des applications populaires comme Snapchat, Fortnite et Alexa sont devenues inaccessibles pendant des heures, exposant à quel point une grande partie d’Internet dépend de quelques grands fournisseurs de cloud.
La panne d’AWS a mis en évidence les points faibles du Web2 et la façon dont les conceptions Web3 ajoutent de la résilience
L’événement a mis en évidence à quel point l’Internet mondial dépend d’un petit nombre de fournisseurs de cloud centralisés. Il a également relancé les discussions autour de modèles alternatifs, en particulier les systèmes décentralisés promus dans le cadre du Web3, qui visent à réduire la dépendance à l’égard des points de défaillance uniques.
Des problèmes de connectivité ont commencé vers 3 h 11 HE, lorsque des utilisateurs aux États-Unis et dans certaines parties de l’Europe ont remarqué que plusieurs applications et sites Web avaient cessé de fonctionner.
Amazon a rapidement confirmé que sa région US-East-1, l’un de ses hubs cloud les plus critiques, connaissait des « taux d’erreur élevés » affectant des services tels que API Gateway, Lambda et CloudFront.
En l’espace d’une heure, les plates-formes dépendantes de l’hébergement AWS, du divertissement aux services aux entreprises, ont commencé à disparaître. La panne d’AWS a perturbé les opérations de base dans de nombreux secteurs, notamment le commerce électronique, les jeux, les communications et les services financiers.
Pendant plusieurs heures, les utilisateurs n’ont pas été en mesure d’accéder aux fonctions de la maison intelligente, de se connecter aux plateformes sociales ou d’effectuer des transactions en ligne. Les entreprises qui opèrent dans des environnements basés sur AWS ont également été confrontées à des temps d’arrêt de leurs systèmes internes, perturbant les opérations quotidiennes et les services à la clientèle.
Cause profonde de la panne AWS : ce qu’Amazon a confirmé
À midi, les ingénieurs d’Amazon ont identifié une erreur de configuration dans une mise à jour du réseau comme étant la cause première. Le problème a perturbé la façon dont les systèmes internes géraient le routage et les opérations DNS, empêchant les requêtes d’atteindre leurs destinations. Les équipes AWS ont annulé la mise à jour défectueuse, rétablissant progressivement le service complet en fin d’après-midi.
Amazon a souligné qu’aucune donnée client n’avait été perdue ou compromise, et que le problème était limité à une seule région. Pourtant, le temps d’arrêt a mis en évidence comment même un problème localisé peut se répercuter sur l’écosystème Web mondial lorsque tant de services numériques dépendent d’une seule couche d’infrastructure.
Quels sites Web et applications sont tombés en panne et pourquoi l’impact s’est propagé
Parmi les perturbations les plus visibles figuraient les propres produits de consommation d’Amazon, notamment Alexa et Ring. Les utilisateurs ont signalé que les haut-parleurs intelligents ne parvenaient pas à traiter les commandes vocales, tandis que les caméras et les sonnettes connectées ne répondaient plus aux commandes des applications mobiles.
Dans le secteur du divertissement et des jeux, des titres tels que Fortnite, Roblox et PUBG ont connu des erreurs de connexion et des échecs de matchmaking. Beaucoup de ces jeux s’appuient sur AWS pour la synchronisation multijoueur en temps réel et la diffusion de contenu dans le cloud.
Les plateformes sociales et de communication ont également été touchées. Les utilisateurs de Snapchat ont rencontré des difficultés pour envoyer des messages et charger des flux pendant le pic de la panne. En outre, Slack, Zoom et plusieurs outils d’entreprise basés sur l’infrastructure AWS ont signalé des problèmes de connectivité intermittents affectant les opérations de travail à distance.
Certaines applications financières et processeurs de paiement qui utilisent les services de calcul et de stockage d’AWS ont été brièvement mis hors ligne, ce qui a entraîné l’échec des transactions et des retards dans les paiements numériques. Les sites Web de vente au détail et de commerce électronique basés sur AWS ont également connu des temps d’arrêt temporaires ou des temps de réponse plus lents.
Pourquoi la centralisation a amplifié le rayon de l’explosion sur le Web
La portée de l’incident a montré à quel point AWS est profondément ancré dans les fonctions quotidiennes d’Internet. Une seule panne régionale s’est étendue au-delà de sa zone géographique immédiate, perturbant les systèmes grand public, de divertissement et d’entreprise sur plusieurs fuseaux horaires.
Cet échec a également mis en évidence comment les dépendances de service, telles que les API et les intégrations de tiers, peuvent propager les effets d’une panne bien au-delà de son origine technique.
Selon le rapport post-incident d’Amazon, l’interruption provenait d’un changement de configuration défectueux déployé lors d’une mise à jour de maintenance de routine. Ce changement a involontairement modifié la façon dont les résolveurs DNS internes dirigeaient le trafic, ce qui a entraîné l’arrêt du traitement des requêtes par les systèmes.
Une fois détectée, les ingénieurs d’Amazon ont lancé une restauration de la mise à jour et redirigé le trafic via des itinéraires de sauvegarde. La restauration a commencé région par région, l’état des pannes AWS montrant une reprise progressive en fin d’après-midi.
Depuis, l’entreprise a mis en place des mesures de protection supplémentaires pour éviter des problèmes similaires, notamment des contrôles plus stricts de la gestion des modifications et de nouvelles procédures de restauration automatisées pour les mises à jour du réseau.
Centralisation et décentralisation : une leçon plus large
Cet incident a rouvert le débat de longue date sur les modèles Web2 vs Web3 . Dans le cadre actuel du Web2, une poignée d’entreprises, dont Amazon, Google et Microsoft, alimentent la majorité du trafic Web mondial via des serveurs centralisés.
Cette structure offre commodité, rentabilité et évolutivité, mais elle concentre également le contrôle et la vulnérabilité. Lorsque l’un de ces fournisseurs subit une perturbation, les effets sont immédiats et généralisés.
Les analystes de l’industrie ont longtemps averti que cette concentration de la puissance d’hébergement et de gestion des données crée un point de défaillance unique pour Internet. Si le cloud computing offre évolutivité et rentabilité, il centralise également les risques. Lorsque les systèmes d’un fournisseur clé tombent en panne, les services dépendants ont peu de marge de manœuvre pour se rétablir indépendamment.
La panne d’AWS a également mis en évidence un autre défi, à savoir les dépendances interconnectées. De nombreux services fonctionnent dans des architectures en couches où l’API ou la base de données d’un fournisseur prend en charge plusieurs plates-formes en aval. Cette structure amplifie l’impact de toute rupture technique.
Les experts suggèrent que si la redondance et le déploiement multi-régions peuvent réduire les risques, le problème fondamental réside dans la façon dont le Web est structuré. Les modèles cloud centralisés consolident le contrôle et la capacité en quelques réseaux, ce qui rend les défaillances à la fois plus percutantes et plus difficiles à isoler.
Pourquoi les experts considèrent le Web3 comme une alternative viable
Le Web3 vise à changer cela en répartissant la puissance de calcul et le stockage des données sur des réseaux décentralisés de nœuds indépendants. Contrairement aux systèmes cloud centralisés, les architectures décentralisées ne dépendent pas du temps de fonctionnement d’un seul fournisseur. En cas de défaillance d’un nœud ou d’un cluster, les autres peuvent continuer à fonctionner sans interruption.
Pour les développeurs et les entreprises, cette approche pourrait signifier une résilience, une transparence et une sécurité accrues, bien que la mise à l’échelle de l’infrastructure décentralisée pour s’adapter à la vitesse et à la capacité du Web2 reste un défi.
Des projets tels que Filecoin, Arweave et Akash Network sont des exemples de solutions d’infrastructure décentralisée qui visent à fournir du stockage et de la puissance de calcul par le biais de réseaux ouverts. Ces systèmes utilisent des mécanismes d’incitation pour maintenir le temps de fonctionnement et la disponibilité des données sans surveillance centralisée.
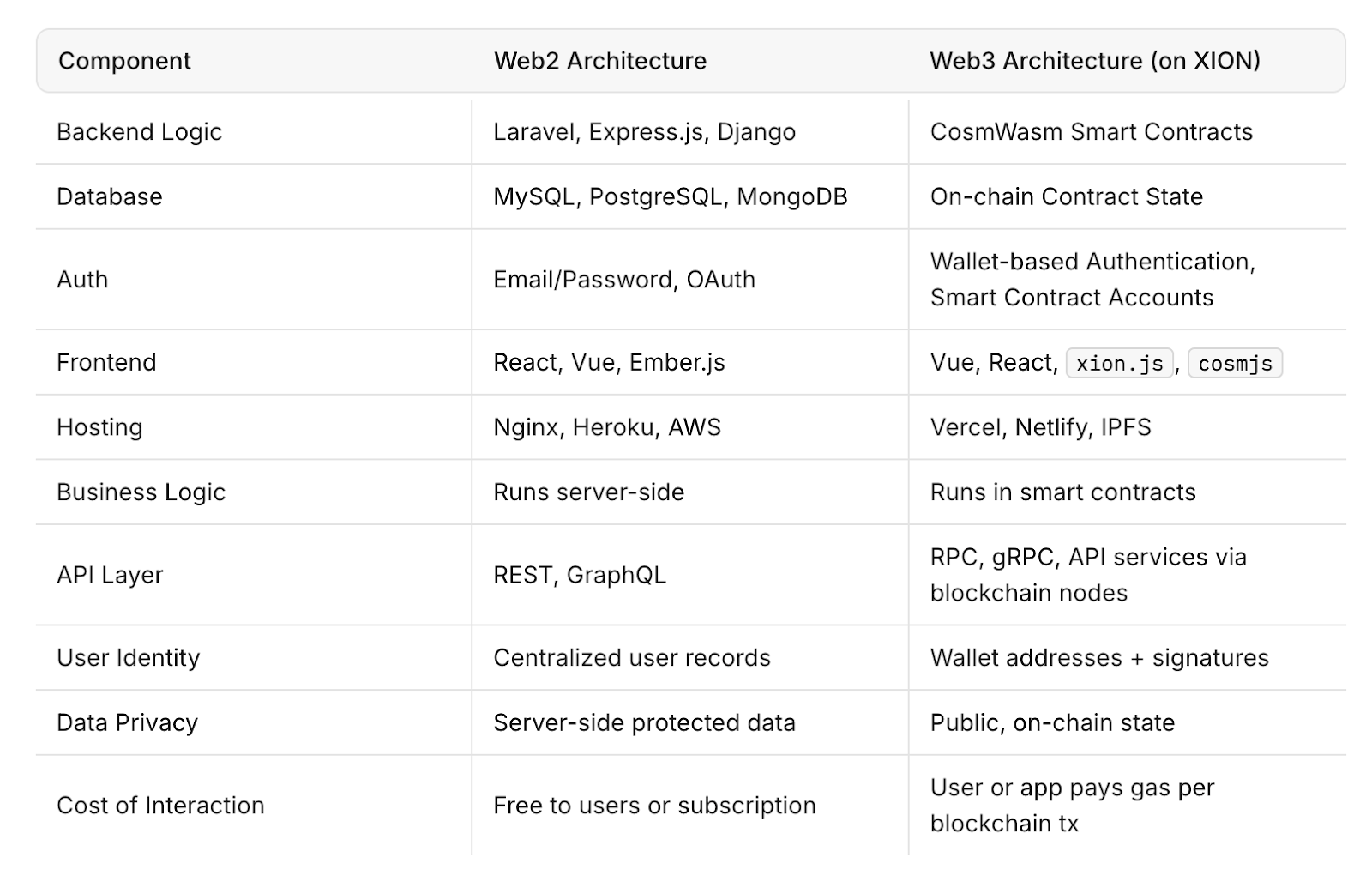
Cependant, l’infrastructure Web3 n’en est encore qu’aux premiers stades de son adoption. Il est confronté à des défis liés à l’évolutivité, à la vitesse et à l’expérience utilisateur par rapport aux systèmes Web2 établis. Malgré cela, l’incident AWS a démontré l’intérêt de disposer de modèles alternatifs susceptibles d’améliorer la résilience d’Internet.
Leçons apprises et voie à suivre
La panne a mis en évidence le fait que la résilience de l’économie numérique nécessite des redondances et des diversifications. Les entreprises qui ont réparti leurs charges de travail sur plusieurs régions ou fournisseurs de cloud ont connu moins de temps d’arrêt et des temps de récupération plus rapides. D’autres, entièrement dépendants d’AWS, ont dû attendre qu’Amazon rétablisse ses systèmes.
Il a également révélé comment les chaînes de dépendance amplifient les perturbations. De nombreuses applications n’ont pas hébergé leurs services principaux sur AWS, mais ont tout de même été mises hors ligne parce qu’elles utilisaient des API hébergées par AWS, des outils d’analyse ou d’authentification. Un seul point de défaillance dans la chaîne a déclenché des pannes sur des plates-formes non liées.
L’événement pourrait inciter plusieurs organisations à repenser leurs stratégies d’infrastructure, en explorant des modèles hybrides qui combinent des systèmes cloud traditionnels avec un stockage et une informatique décentralisés.
Les développeurs et les entreprises peuvent également considérer la décentralisation non seulement comme une tendance, mais aussi comme une protection pratique contre les temps d’arrêt à grande échelle.
Amazon a déclaré que de nouveaux mécanismes de surveillance et des contrôles internes de restauration sont désormais actifs dans toutes les régions. Cependant, les experts notent que les correctifs techniques ne peuvent à eux seuls résoudre pleinement les risques inhérents à la centralisation.
À mesure que la dépendance numérique mondiale s’intensifie, la résilience peut dépendre de l’efficacité de la coexistence de l’informatique en nuage et des technologies décentralisées.
FAQs
Qu’est-ce qui a causé la panne d’AWS ?
Amazon a déclaré qu’une erreur de configuration lors d’une mise à jour de routine dans sa région US-East-1 avait perturbé le routage du réseau et les fonctions DNS. Le problème a été contenu en quelques heures, et aucune violation de données ou de sécurité n’a été signalée.
Quels sites Web et applications ont été touchés ?
Des plateformes telles qu’Alexa, Ring, Snapchat, Fortnite et Roblox ont été mises hors ligne. Les outils commerciaux et de paiement utilisant l’infrastructure AWS ont également été confrontés à des interruptions temporaires.
Pourquoi la centralisation rend-elle Internet vulnérable ?
Les systèmes centralisés s’appuient sur quelques fournisseurs majeurs, de sorte qu’une défaillance peut affecter des millions d’utilisateurs. Les réseaux décentralisés réduisent ce risque en répartissant les opérations sur des nœuds indépendants.
Conclusion
L’incident d’octobre 2025 a révélé les forces et les faiblesses de l’infrastructure cloud moderne. AWS a réussi à rétablir rapidement ses opérations, mais les effets d’entraînement mondiaux ont montré que la fiabilité a des limites lorsque le contrôle repose sur quelques fournisseurs.
Pour les entreprises et les développeurs, la leçon à tirer est que la diversification et la décentralisation ne sont plus facultatives. Les infrastructures hybrides qui allient efficacité centralisée et résilience décentralisée pourraient définir la prochaine ère de fiabilité d’Internet.
Disclaimer: The information presented in this article is for informational and educational purposes only. The article does not constitute financial advice or advice of any kind. Coin Edition is not responsible for any losses incurred as a result of the utilization of content, products, or services mentioned. Readers are advised to exercise caution before taking any action related to the company.




